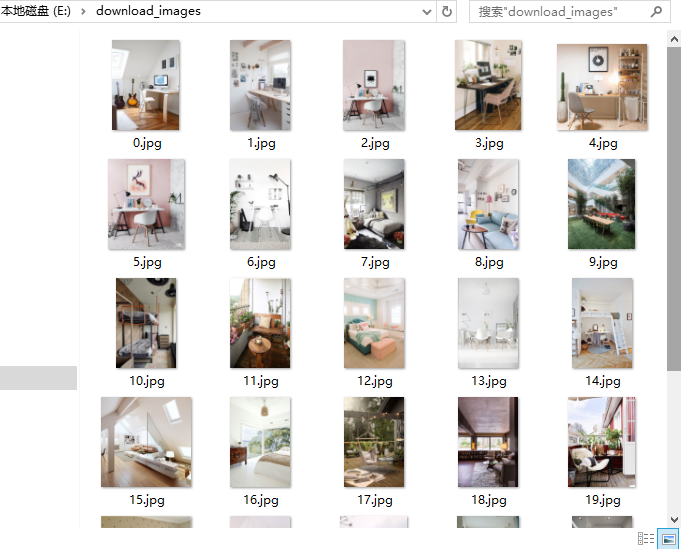
动态爬虫花瓣家装图片

装房子时,可能会想收集一些装修作为参考图片,此时可以利用爬虫爬取某个关于家装的专题图片,在花瓣上找了一个专题,学了下简单的爬虫知识,接下来简单记录下思路。
基本步骤
发送请求->获取到html内容->分析DOM结构->解析DOM结构->正则匹配或其他库提取数据->数据后续加工处理
步骤
找到要爬取的网址, 如家装专题,该页面以瀑布流的方式布局,查看源代码并分析其布局,所有的图片都包裹在一个id为waterfall的div中
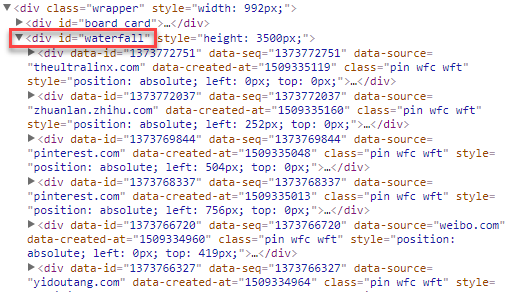
通过xpath获得该div下的所有div,并取得包裹其中的image的缩略图地址。
但该缩略图片太小,需要点击图片进入到预览模式,下载其原始尺寸的图片。
点击其中一张图片,打开大图模式,如:http://huaban.com/pins/1373772751/ ,直接从该地址开始爬取,看不到浏览下一张的按钮(直接浏览器打开是看不到左右切换图片的按钮)。下一张图片与当前图片的id并不是连续的,所以只能从缩略图那里点击进入预览模式,这里选择点击第一张缩略图获得其大图页面的url。
1 | water_falls = driver.find_elements(By.CLASS_NAME, "cover") |
此时需要对浏览器进行操作,使用selenium驱动浏览器,依次浏览所有的图片
1 | right_arrow = WebDriverWait(driver, 10).until( |
每点击一次,获取当前页面内容,并提取图片的地址
1 | html = driver.page_source |
获取到图片的url后,下载保存到本地
1 | path = r'E:\download_images' # 图片保存地址 |
最后通过循环定义要下载的数量就OK了。